满足您所有代币化需求的一站式商店
介绍
对于新手来说,让我们从正式引入标记化的概念开始-标记化只是将输入文本数据拆分为单独的有意义的标记的一种方法,这些标记可以被机器进一步理解和处理。标记可以是单词、字符,甚至是子单词,这取决于所使用的拆分算法。在本文中,我们将讨论所有三大类标记——单词、字符和子单词。我们还将关注大多数最近的SOTA模型使用的子词标记化算法-字节对编码(BPE)、词块、单字和句子块。在本次讨论结束时,您将对上述每一种途径都有了具体的了解,并将能够决定哪种标记化方法最适合您的需求。
基于词的标记化
顾名思义,在基于单词的标记化方法中,由标点符号、空格、分隔符等分隔的整个单词被视为标记。分离边界可以是特定于任务的,有时可能取决于您正在处理的数据的性质。用于标记Twitter推文的基于单词的标记器与用于标记新闻文章本身的标记器略有不同。
为了更好地理解这一点,让我们从一个示例开始,展示仅基于空白字符执行的标记化

Space Tokenization
通过这种方法,您可以看到“标记化!”被视为单个令牌。如果要在更大的数据集上运行它,这种方法将导致巨大的词汇表,因为无数的单词和标点符号分组将被视为与基础单词不同的标记。为了解决这个问题,让我们尝试对标点符号和空白进行标记化。

Space and Punctuation Tokenization
结果现在看起来比以前的输出要好一点。尽管如此,我希望您会理解,在英语中,并非所有标点符号都可以被视为符号边界,而不理解它们所处的上下文。将其置于上下文中,我们理想地希望在这些场景中以不同的方式对待撇号-“让我们”和“不”——[“做”、“不”]标记将提供更有意义的语义,即[“不”、“”、“t”],而我们可以使用[“让”、““”、“'s”]。
这将我们带到基于规则的单词标记器的主题。SpaCy提供了一个很棒的基于规则的标记器,它应用特定于语言的规则来生成语义丰富的标记。感兴趣的读者可以偷窥一下spacy定义的规则。

Rule-based Tokenization — SpaCy
这种方法非常简单,如果您能够忍受过多的处理时间和处理能力,那么它在大多数情况下都能很好地工作。否则,还有一个警告-随着训练数据的增加,词汇也会增加。在一个巨大的语料库上训练一个具有这种基于词的标记化的模型将产生一个具有过高资源需求的极其沉重的模型。
那么,为什么不使用字符集作为标记来减少词汇表的大小呢?
基于字符的标记化
可以想象,基于字符的标记化将所有基本字符视为标记。根据您的要求,它们可以是UNICODE、ASCII等。继续上面的示例,结果如下:

Character-based Tokenization
当然,模型的复杂性和大小将大大降低,因为词汇表非常有限,只有大约200个标记。然而,标记不再具有有意义的语义。将其置于上下文中,基于词的标记化中的“国王”和“王后”的表示将包含比字母“k”和“q”的上下文独立嵌入更多的信息。这就是语言模型在基于字符的标记上训练时表现不佳的原因。
如果性能对您的业务需求不是至关重要的,并且愿意为了更高的速度和更少的计算密集度而牺牲性能,那么就使用它。
否则,如果您想要两全其美,则标记化算法必须找到一个中间点,该中间点可以保留尽可能多的语义有意义的信息,同时在一定程度上限制模型的词汇量。认识我们的新朋友,子词标记化!
基于子词的标记化
如果基于字符和文字的标记化不能让你的船漂浮起来,这是你应该保证的最佳点-不受无意义标记的限制,也不太需要时间和处理能力。子词标记化方法的目标是只使用多达N个标记来表示数据集中的所有词,其中N是超参数,根据您的需求决定。一般来说,对于基础模型,它大约在30000个代币左右徘徊。多亏了这些方法,不需要无限的词汇表,我们现在可以很好地捕获上下文无关的语义丰富的令牌表示。
我们现在将讨论一些用于执行子词标记化的最佳和广泛使用的算法。
字节对编码(BPE)
字节对编码首先需要对输入文本进行预标记化-这可以像空白标记化一样简单,也可以使用基于规则的标记器(如SpaCy)来执行预标记化步骤。
现在我们形成了一个基本词汇表,它只是语料库中所有独特字符的集合。我们还计算每个标记的频率,并将每个标记表示为基础词汇表中的单个字符列表。
现在合并开始了。只要不违反以下标准的最大大小,我们将继续向基本词汇添加标记-出现次数最多的标记对被合并并作为新标记引入。重复此步骤,直到我们达到配置的最大语音大小。
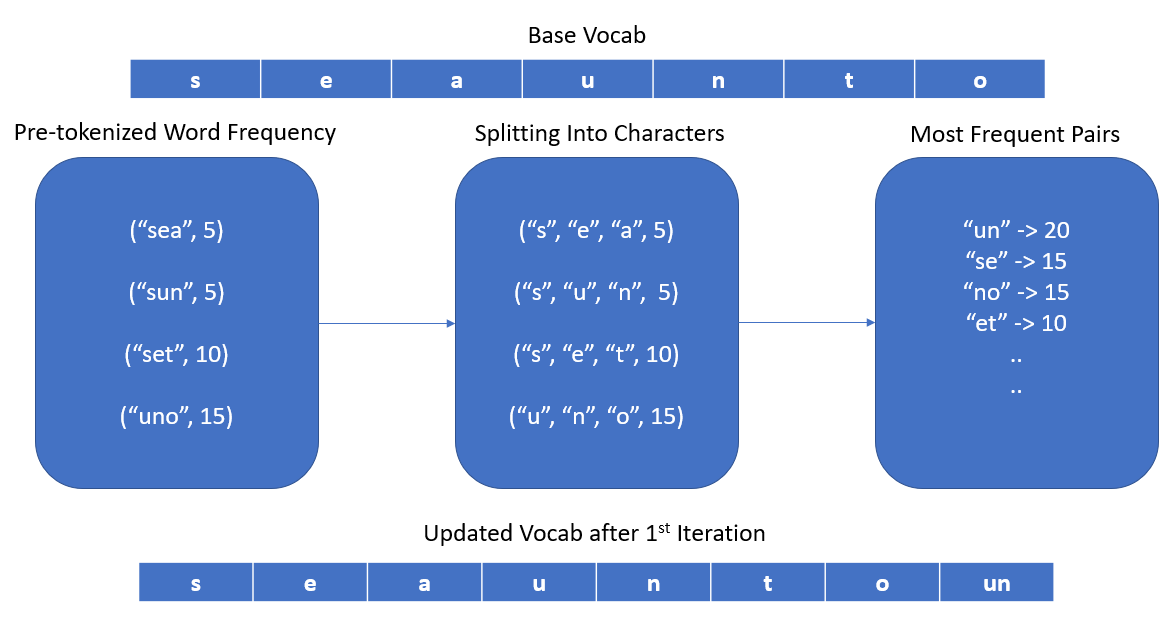
Byte-Pair Encoding Algorithm
词条
词块和BPE在实现子词标记化的方法上非常相似。在我们看到BPE之前,主要标准是选择具有最大频率的候选对。词块,而不是最大化频率,专注于最大化候选对的可能性-这可以简洁地总结为以下公式:

一元模型
使用BPE的一个缺点是,当标记一个单词时存在歧义时,它无法提供一种用于选择标记的排序机制。为了更好地理解这一点,假设我们的基本词汇由以下符号组成-the,th,at,eat,re,如果我们被要求将单词“theatre”符号化,我们将得到两个选项,其中一个都不在另一个之前-(the,at,re)或(th,eat,re)。BPE专注于每个步骤的最佳预测,这更像是一个贪婪的解决方案,因此在某些情况下可能产生不太可能的结果。然而,Unigram坚持预测最可能的结果标记,同时考虑训练期间的学习概率。
在训练的每个阶段,我们计算每个子词标记的概率,并定义如果每个子词令牌被丢弃将导致的损失值。然后,我们挑选掉掉的话会导致最小总体损失的标记,本质上是那些给集合增加很少价值的标记。
句子
现在是最后一个,也是NLP社区所见过的最巧妙的方法之一。到目前为止,句子块就像本文中描述的所有子词标记化方法之父。它与语言无关-适用于所有语言,因为它不需要预标记器来处理特定于语言的属性。它将空格视为一个单独的符号,从而完全解决了解码问题(我知道这听起来很简单!)。总体而言,它比其他子词标记化方法更快,使其成为大多数用例的标记器。为了进一步阅读,你可以查阅已发表的句子文章。
在本文中,我们介绍了一些最佳和广泛使用的标记化算法,权衡了它们的优缺点,并讨论了它们可能是正确选择的情况。希望您现在装备精良,能够更轻松地处理不同的标记化策略!
- 登录 发表评论